70M offline messages... What?

When working on the 1.9.0 release an IoT company contacted us to help them improve their VerneMQ setup. The customer wanted to use VerneMQ as a highly available buffer to store incoming messages. That way their consumer applications can be offline for many hours. They wanted to buffer as many as 1M messages for every connected subscriber.
They encountered two main challenges:
- It took a single VerneMQ cluster node more than one hour to start.
- MQTT clients run into timeouts when connecting to the broker.
At first, we tried to investigate if using larger VM instances would make a difference. So we configured VMs that have more CPUs and RAM available, but this didn't have the desired impact. We've discovered a VerneMQ bottleneck.
First Iteration
After the first analysis, we realized that we can't fix the issue by throwing more hardware at the problem. We had to dig deeper.
We received a dump of their data and started analyzing where VerneMQ spends most of the startup time. We figured out that the LevelDB backed message store is the main time consumer. As we hadn’t invested much in optimizing the message store we weren't surprised to see that. So far initializing the message store required a full scan of the data and afterwards during queue initialization we would in essence iterate over the data one more time. Instead we managed to simplify the initial scan and during the scan to build an in-memory data structure holding the data needed for the queue initialization, completely avoiding the second iteration over the message store. One very nice optimization was that the new data structure has a time complexity of O(n log n)) whereas the old has a complexity of O(n2) which is of course important when the number of messages gets large. A final touch was that the new code increased the parallelism and was therefore much better able to fully utilize the available CPUs.
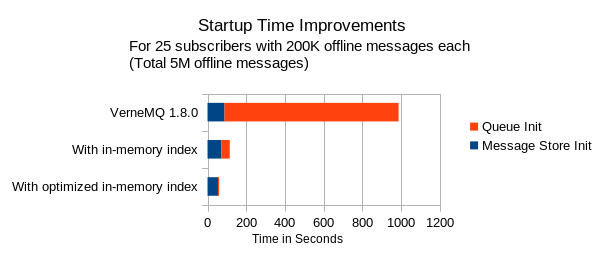
Second Iteration
When hiking up a mountain you're pleased to finally see the top, only to be disappointed a few steps further as the real summit creeps into view, towering overhead. Like this it is with bottlenecks in software. When removing one, the next one appears.
At this point we were able to initialize the queues with dramatic improvements in performance, but there was still an issue when the clients connected. It would just take forever. The reason for this was that we'd try to immediately dispatch all the (millions) of messages to the client, which involved reading in the payload from disk for each message. This could of course take quite some time and might sometimes even be wasted work as the client might not consume a lot of messages before disconnecting again. Luckily this was very simple to mitigate as we could simply dispatch small chunks instead of the all the messages. With that simple patch clients with huge queues were able to connect and start receiving messages almost immediately.
Third Iteration
With the previous improvements, clients with large queues were now able to connect... most of the time.
We realized that another challenge handling very large message queues is queue migration. VerneMQ automatically migrates queues when clients hop from one cluster node to another. Appropriate load balancer strategies can be used to avoid queue migrations, but it should of course be possible to migrate a queue even if it contains millions of messages. Investigating the queue migration code we learned that the migration itself isn't the issue. It is rather the time it takes to complete a migration which for very large queues can take a long time and as a consequence, the clients experienced connection timeouts. We managed to improve this situation by ensuring that the migration doesn't block the client and the client can start consuming the migrated messages immediately.
Conclusion
Those improvements enabled the customer to simulate the expected load. All the fixes are part of the 1.9.0 release.